%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Self-Supervised Learning
SHMT
SHMT is a self-supervised hierarchical makeup transfer technology achieved through latent diffusion models. This technology allows for the natural transfer of one facial makeup to another without the need for explicit labeling. Its main advantages include the ability to handle complex facial features and expression changes, providing high-quality transfer results. This technology has been accepted at NeurIPS 2024, showcasing its innovation and practicality in the field of image processing.
AI design tools
48.0K
1.58 Bit FLUX
1.58-bit FLUX is an advanced text-to-image generation model that employs 1.58-bit weights (values of {-1, 0, +1}) to quantify the FLUX.1-dev model while maintaining comparable performance for generating 1024x1024 images. This method does not require access to image data and relies entirely on the self-supervision of the FLUX.1-dev model. Additionally, a custom kernel has been developed to optimize 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x decrease in inference memory, and improved inference latency. Extensive evaluations in GenEval and T2I Compbench benchmarks show that 1.58-bit FLUX significantly enhances computational efficiency while maintaining generation quality.
Image Generation
79.5K

Video Foley
Video-Foley is an innovative system for generating sound from video. It employs root mean square (RMS) as a temporal event condition, combined with semantic tonal prompts (audio or text), to achieve high control and synchronization in video sound synthesis. The system utilizes an unsupervised learning framework that requires no manual labeling, consisting of two stages: Video2RMS and RMS2Sound, incorporating novel concepts such as RMS discretization and RMS-ControlNet, in conjunction with a pre-trained text-to-audio model. Video-Foley achieves state-of-the-art performance in aligning and controlling sound timing, intensity, timbre, and detail.
AI video generation
58.2K
Fresh Picks
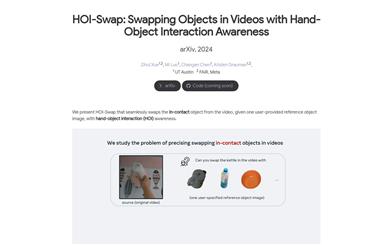
HOI Swap
HOI-Swap is a diffusion model-based video editing framework specializing in tackling the complexities of hand-object interactions in video editing. This model, trained through self-supervision, enables seamless object swapping within a single frame. It also learns to adjust hand interaction patterns based on object attribute changes, such as grip style. The second stage extends single-frame editing to an entire video sequence, achieving high-quality video editing through motion alignment and video generation.
Video Editing
56.3K
Fresh Picks
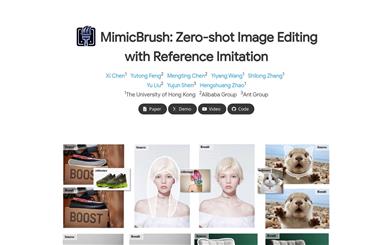
Mimicbrush
MimicBrush is an innovative image editing model that allows users to achieve zero-shot image editing by specifying the editing area in the source image and providing a reference image. The model can automatically capture the semantic correspondence between the two images and complete the editing in one step. MimicBrush is developed based on diffusion priors, capturing semantic relationships between different images through self-supervised learning, and experimental results demonstrate its effectiveness and superiority in various test cases.
AI image editing
477.2K

Denseav
DenseAV is a novel dual-encoder localization architecture that learns high-resolution, semantically meaningful audio-visual alignment features by observing videos. It can discover the "meaning" of words and the "location" of sounds without requiring explicit localization supervision, and automatically discovers and distinguishes between these two types of associations. DenseAV's localization capability stems from a new multi-head feature aggregation operator, which directly compares dense image and audio representations through contrastive learning. Additionally, DenseAV significantly outperforms previous art on semantic segmentation tasks and surpasses ImageBind in cross-modal retrieval using less than half the parameters.
Video Editing
55.8K

Anitalker
AniTalker is an innovative framework that can generate realistic dialogue facial animations from a single portrait. It enhances expressive motion capture through two self-supervised learning strategies, and develops an identity encoder through metric learning, effectively reducing the need for labeled data. AniTalker not only creates detailed and realistic facial expressions but also emphasizes its potential in real-world applications for producing dynamic avatars.
AI head portrait generation
121.4K
Miqu 1 70b
Miqu 1-70b is an open-source large language model that utilizes novel self-supervised learning methods, capable of handling a variety of natural language tasks. With 170 billion parameters, it supports multiple prompt formats and allows for fine-tuning to generate high-quality text. Its strong comprehension and generation capabilities make it suitable for applications in chatbots, text summarization, question answering systems, and other domains.
AI Model
121.4K
A Vision Check Up
This paper systematically evaluates the ability of large language models (LLMs) to generate and recognize increasingly complex visual concepts, and demonstrates how to train initial visual representation learning systems using text models. Although language models cannot directly process pixel-level visual information, this research utilizes code representations of images. While LLM-generated images are not like natural images, the results on image generation and correction suggest that accurately modeling strings can teach language models much about the visual world. Furthermore, experiments on self-supervised visual representation learning using text-model generated images highlight the potential of training visual models capable of semantic evaluation on natural images using only LLMs.
AI Science Research
50.5K
Featured AI Tools
Chinese Picks

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
154.0K
Fresh Picks

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
113.7K
English Picks

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
133.9K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
100.5K
English Picks

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
66.8K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
90.5K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
662.4K
Chinese Picks

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M